Notes on 'DoS due to inv-to-send sets growing too large' from May 2023
When non-ideal sorting, BRC-20 mints, and spy nodes caused a CPU Denial-of-Service on the Bitcoin network
Tuesday, June 24, 2025In October 2024, the Bitcoin Core project disclosed a Denial-of-Service due to inv-to-send sets growing too large, which I authored, for Bitcoin Core versions before v25.0. I have a few notes and screenshots from my investigation back then that I want to persist here. In early May 2023, my monitoring infrastructure noticed this bug affecting mainnet nodes, which allowed me to pinpoint where the problem came from. Credit for working on a fix goes to Anthony Towns.
Observation
On May 2nd, 2023, I noticed that on one of my monitoring nodes, the inbound connections had dropped from about 1901 to only 35 over about two days. Normally, a node keeps its filled inbound slots until it restarts or loses network connectivity.
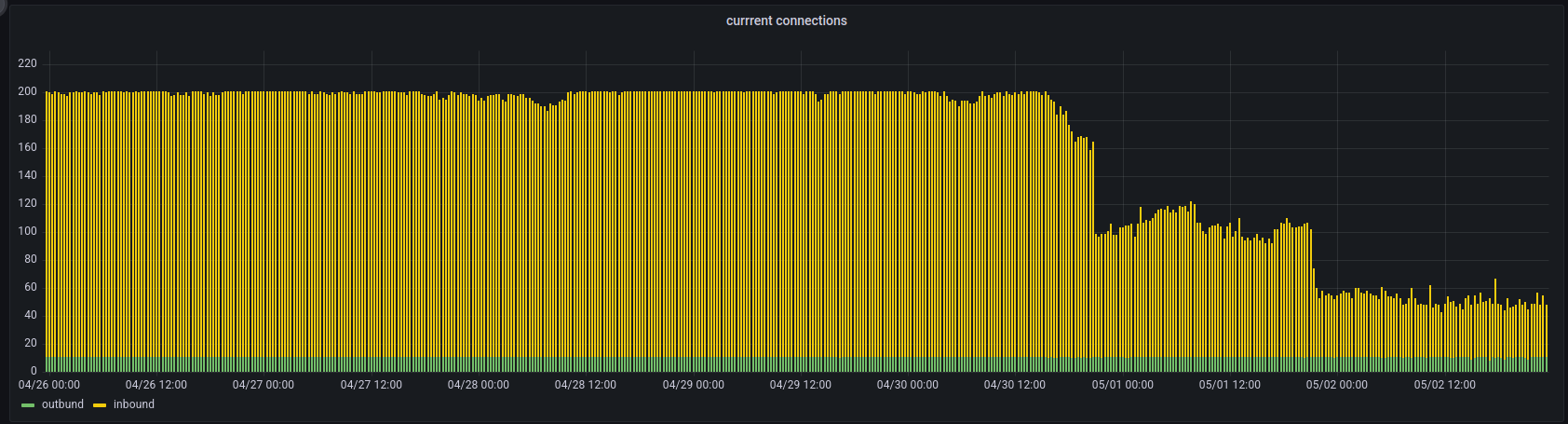
Checking in with other contributors, I noticed the node had 100% CPU utilization. This affected the node to a point where it could not to keep communicating with its peers, which resulted in inbound connections timing out and dropping. Using perf top on the node process, I could see that a lot of CPU time was being spent on CTxMemPool::CompareDepthAndScore() in the b-msghand thread. I recorded the following flamegraph, which shows that make_heap(), which calls CompareDepthAndScore(), used over 45% of the CPU time of the process.

At the same time, there was an open, unrelated 100% CPU usage issue with debug mode builds of Bitcoin Core. This confused some contributors and users who weren’t running debug mode builds but noticed the high CPU usage on their nodes. While the debug mode issue likely only affected some developers, the other high CPU usage issue affected the entire network. This included, for example, mining pools such as AntPool and others, who reported problems with their mining operations because to their nodes failing to process received blocks in a timely manner.
Effect
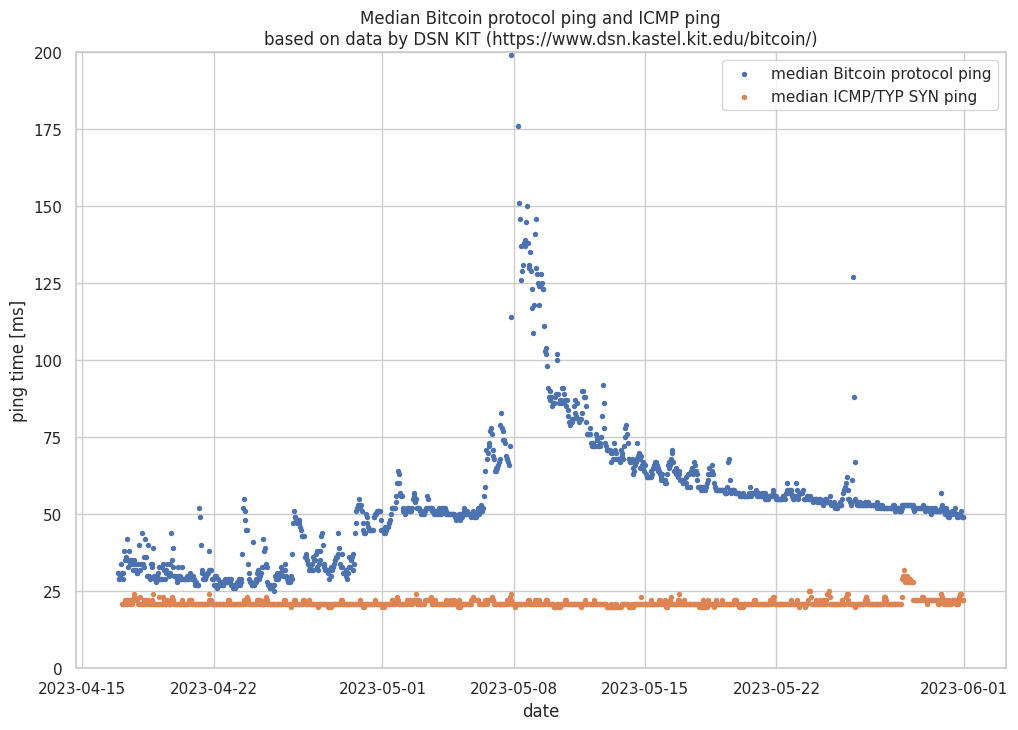
Observing ping timings across the network reveals the effect of this Denial-of-Service. Since Bitcoin Core’s message processing is single-threaded, only one message can be created or processed at a time, meaning that all other peers have to wait. Longer wait times impact the response time for a ping. The KIT DSN Bitcoin monitoring has data on ICMP and Bitcoin protocol pings. Comparing these allows us to determine when node software has problems keeping up with message processing. The data shows the ICMP ping to the host remained unaffected, however, the median ping to the Bitcoin node software nearly doubled from about 25ms to more than 50ms between the end of April and early May. The median Bitcoin ping spiked to 200ms on May 8th, while the ICMP ping remained unaffected.
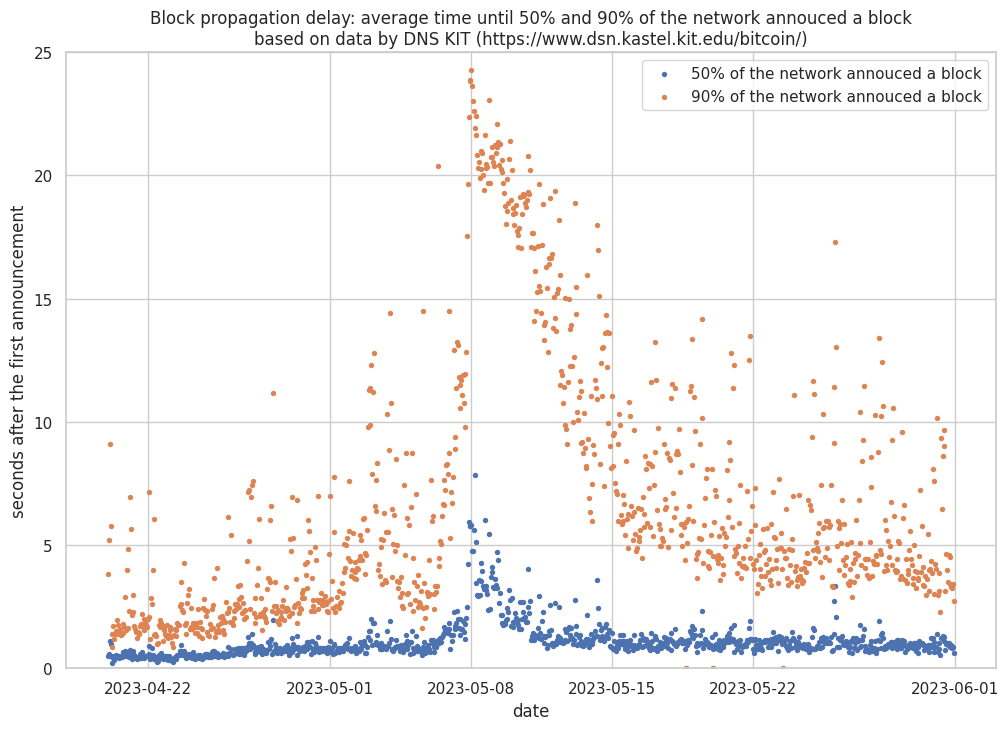
The effect can also be seen by looking at the block propagation delay data collected by the KIT DSN Bitcoin monitoring. Around May 8th, 2023, a spike in the block propagation delay is visible. The time it took 50% of the reachable nodes to announce the block to their monitoring nodes increased from less than a second to more than five seconds. Similarly, the 90% measurement spiked from about two seconds to more than 20 seconds.
Bad block propagation also causes more stale blocks as mining pools mine on their outdated blocks for longer, while a new block they haven’t seen yet already exists in the network. Based on the data from my stale-blocks dataset, ten stale blocks were observed during the week between May 3rd (starting with stale block 788016) and May 10th (and ending with block 789147). That’s a rate of about 8.84 stale blocks per 1000 blocks. In comparison, between blocks 800000 and 900000 (about two years), 73 stale blocks were observed. This is a rate of 0.73 stale blocks per 1000 blocks. This 10-fold increase in the stale-block rate was likely caused by block propagation being significantly affected.
Cause
Why did the function CTxMemPool::CompareDepthAndScore() slow down the node to a point where it had trouble processing P2P messages? In Bitcoin Core, the b-msghand thread processes P2P messages. For example, passing newly received blocks to validation, responding to pings, announcing transactions to other peers, and a lot more.
The function CTxMemPool::CompareDepthAndScore() is used when deciding which transactions to announce to a peer next. In the Bitcoin P2P protocol, transactions are announced via inv (inventory) messages. A Bitcoin Core transaction announcement to a peer usually contains up to 35 wtxid entries. To keep track of which transactions to announce to a peer next, there is a per-peer m_tx_inventory_to_send set. It contains the transactions the node thinks the peer hasn’t seen yet. When constructing an inventory message for a peer, the set is sorted by transaction dependencies and feerate to prioritize high-feerate transactions and to avoid leaking the order the node learned about the transactions. For this, the CTxMemPool::CompareDepthAndScore() comparison function is used.
In early May 2023, a huge amount of transactions related to BRC-20 tokens were broadcast. This meant that the m_tx_inventory_to_send sets grew faster than usual and larger than usual. As a result, sorting the sets took more time. On evening of May 7th (UTC), the mint of the VMPX BRC-20 token started, which resulted in more than 300k transactions being broadcast in 6h next to the other ongoing BRC-20 token mints. This caused the spikes in median ping and block propagation times observed on May 8th.
The effect is amplified by so-called spy nodes which only listen to inv messages and never announce transactions on their own. When a peer announces a transaction to a node,
the node can remove it from their m_tx_inventory_to_send set as it’s known by the peer and does not need to be announced anymore. This meant that the sets for spy nodes were even larger and took even more time to sort as they were drained more slowly. Spy nodes, for example, LinkingLion and others, are common and often have multiple connections open to a node in parallel. At times, I count more assumed spy nodes than non-spy node connections to my nodes.
The huge amount of transactions being broadcast, combined with amplification by spy nodes, and non-optimal sorting of the large m_tx_inventory_to_send sets by CTxMemPool::CompareDepthAndScore() caused nodes to spend a lot of time creating new
inventory messages for transaction relay. Since message handling is single-threaded, communication with other peers was significantly slowed down. This reached a point where blocks weren’t processed in a timely manner and some connections timed out.
Fix
The fix is twofold. First, all to-be-announced transactions that were already mined or for some other reason not in the mempool anymore, were removed before the m_tx_inventory_to_send set was sorted. Previously, these transactions were removed only after the set was sorted. This avoids spending time on sorting transaction entries that will never be announced anyway and reduces the size of the to-be-sorted set. Secondly, when the m_tx_inventory_to_send sets are large, the number of entries to drain from the set is dynamically increased based on the set size. This means that when many transactions are broadcast, a node will announce more transactions to its peers until the sets are smaller again. The fix was backported in time for the v25.0 release at the end of May 2023.
Reflection
While a set of regular contributors knew that this was going on, this issue was not openly communicated to the public. The 100% CPU usage issue with debug mode being discussed at the same time caused confusion, even among regular Bitcoin Core contributors. At the time, I had the feeling that this could and maybe should be fixed quietly and doesn’t need a lot of publicity for the time being. In hindsight, maybe being more public and transparent with the issue could have worked too. The high number of BRC-20 broadcasts only lasted for about a week (but this wasn’t known beforehand) and restarting the node would have helped for a while. To mitigate the issue for, for example, mining pools that can’t upgrade to a version with the fix immediately (due to running with custom patches), a ban list of spy nodes was prepared, but I don’t know if it was ever used.
While there was no dedicated communication channel for this event, a non-listed IRC channel with P2P contributors was used and interested contributors were invited or informed about the events via direct messages. As far as I’m aware, there was no incident response channel and I don’t know if one would be helpful given the ad hoc and decentralized nature of Bitcoin development. No contributor is responsible for incident response, but everyone can help.
Personally, I’m happy that my monitoring proved to be useful for this. While I didn’t have alerting for dropped connections set up at the time and only noticed it by looking at the dashboard, it was helpful to have it. To pinpoint the issue, having a few nodes to play around with and run, for example, perf top on was helpful. Future monitoring should include ping times and alerting on dropped connections.
I had increased the connection count from the default 125 connection to 200. ↩︎
My open-source work is currently funded by an OpenSats LTS grant. You can learn more about my funding and how to support my work on my funding page.
 Text and images on this page are licensed under the Creative Commons Attribution-ShareAlike 4.0 International License
Text and images on this page are licensed under the Creative Commons Attribution-ShareAlike 4.0 International License
